Insights

Data Migration to Hadoop Delivers 80% Cost Savings While Improving Performance for Bank
THE CHALLENGE
To reduce costs, our financial customer needed to migrate all their business and banking data from Teradata to Hadoop. But the data to be migrated was extremely sensitive and essential for daily business activities, which meant the migration needed to be highly secure with no downtime. To add to the complexity, the data came from multiple banking sectors such as financial data, loans, credit cards, and consumer banking, each with its unique migration challenges. Our customer needed a technology partner that could handle these challenges and complete the data migration in just 18 months.
THE SOLUTION
Beyondsoft was chosen to plan and implement the migration from Teradata to Hadoop. Initially, our customer had estimated the scope of the migration to be 2,000 tables with 2,800 objects. However, once Beyondsoft initiated the work, we found they had inadvertently miscalculated and that there were actually 6,000 objects, making the 18-month project timeline even more challenging.
Additionally, because the migration source and destination were very different, to avoid data and functionality issues, Beyondsoft needed to redefine the data architecture. By redesigning the architecture to accommodate the destination format, Beyondsoft achieved performance improvements and complied with end-user requirements.
Furthermore, to avoid disrupting any services that were dependent upon the data, Beyondsoft worked with the customer to create a prioritization plan for the migration, starting with the most frequently used data first and ending with infrequently used data. Throughout the project, Beyondsoft ensured that more than 100 user entities who required data did not see any downtime, even when occasional issues were encountered.
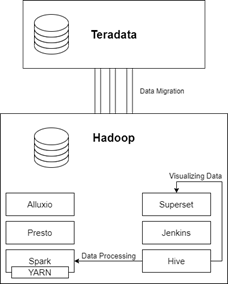
The redesigned Hadoop architecture
THE RESULTS
The data migration was a resounding success, delivering the following benefits to our customer:
- Migration from Teradata to Hadoop with no downtime.
- On-time project completion.
- Reduced data costs by 80%.
- Achieved a 30% performance improvement.
TECHNOLOGIES USED
Beyondsoft used the following technologies:
- Presto as a query engine
- Alluxio for data orchestration
- Apache Hive for managing tasks and collaboration
- Yarn as a package manager
- Jenkins as an automation server
- Apache Superset for data exploration and data visualization
- Apache Spark for data processing

How we do it
Our success factors over the years are a testament to driving your return on investment. Singapore is our global head office and we have 15 regional offices around the world.

Three decades of strong IT consulting and services

Global presence across four continents

Certifications* in CMMI 5, ISO 9001, ISO 45001, and ISO 27001

>30,000 global experts

Microsoft Azure Expert MSP
ISO 9001 and 45001 (certificates issued to Beyondsoft International (Singapore) Pte Ltd). ISO 27001 (certificates issued to Beyondsoft International (Singapore) Pte Ltd, Beyondsoft (Malaysia) Sdn. Bhd., and Beyondsoft Consulting Inc., Bellevue, WA, USA)